Overview
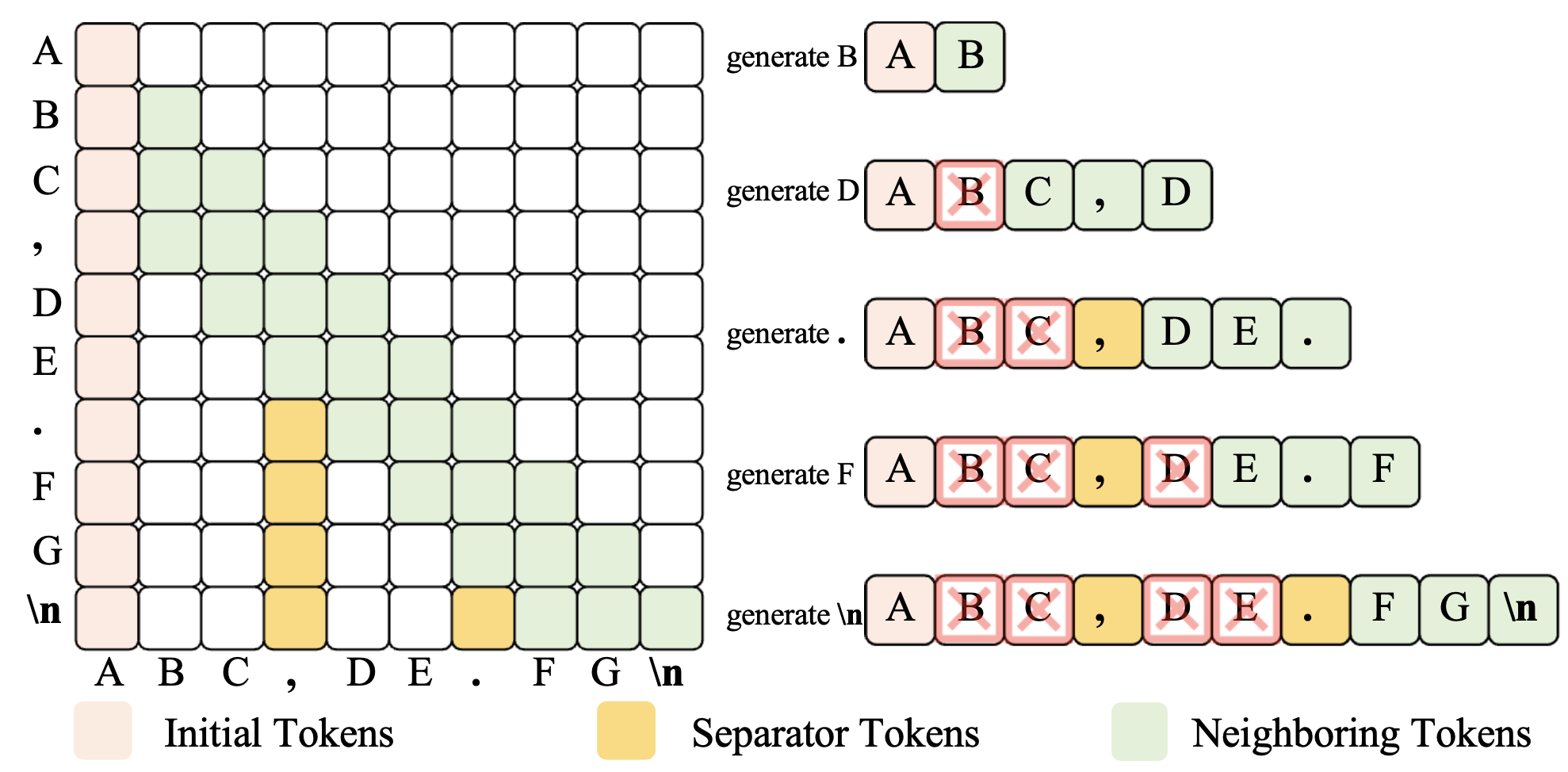
Figure 1: The training and inference paradigm of SepLLM.

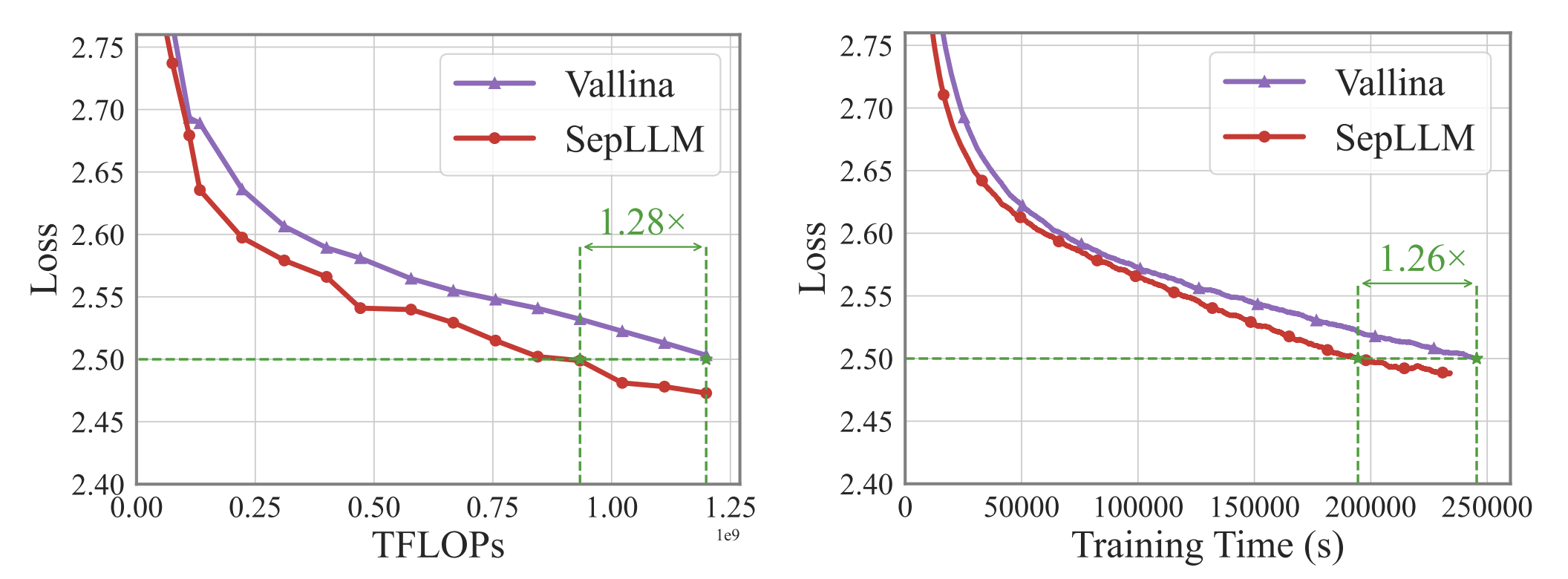
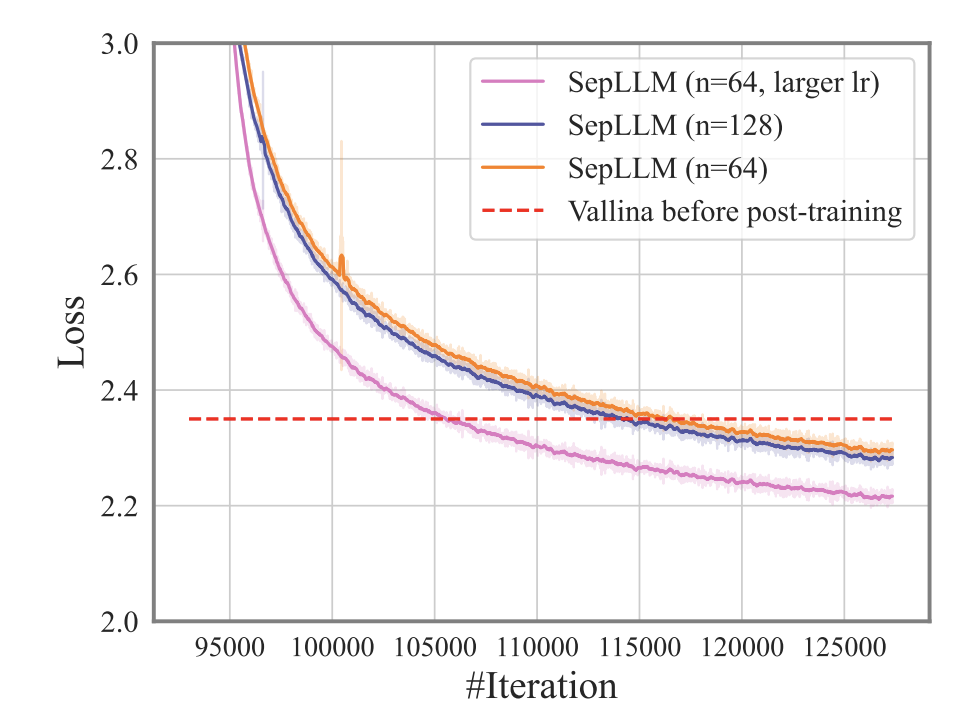
Large Language Models (LLMs) have exhibited exceptional performance across a spectrum of natural language processing tasks. However, their substantial sizes pose considerable challenges, particularly in terms of computational demands and inference speed, due to its quadratic complexity. In this work, we have identified a noteworthy pattern: certain meaningless special tokens (i.e., separators) contribute massively to attention scores compared to other semantically meaningful tokens. This insight has led us to hypothesize that the information of the segment between these special tokens can be condensed into these tokens without significant loss of information. Based on this hypothesis, we introduce SepLLM, a plug-and-play framework for inference acceleration by compressing these segments and dropping redundant tokens. Besides, we implement efficient kernels for training acceleration. The experimental results on training-free, training-from-scratch and post-training settings substantiate the effectiveness of SepLLM. Notably, SepLLM achieves a remarkable reduction of over 50% in KV cache on the GSM8K-CoT benchmark, utilizing the Llama-3-8B backbone, with negligible compromise in performance. Additionally, in streaming settings, SepLLM is capable of delivering consistent and effective language modeling across up to 4 million tokens or even more.
| GSM8K-CoT | r.KV(%) | MMLU | r.KV(%) | |
|---|---|---|---|---|
| Vanilla | 77.3 | 100.0 | 65.7 | 100.0 |
| StrmLLM (n=380) | 71.4 | 47.5 | 63.4 | 52.5 |
| StrmLLM (n=256) | 68.6 | 26.0 | 62.1 | 37.7 |
| SepLLM (n=256) | 77.2 | 47.4 | 64.7 | 44.6 |
@inproceedings{chen2025sepllm,
title={{SepLLM: Accelerate Large Language Models by Compressing One Segment into One Separator}},
author={Chen, Guoxuan and Shi, Han and Li, Jiawei and Gao, Yihang and Ren, Xiaozhe and Chen, Yimeng and Jiang, Xin and Li, Zhenguo and Liu, Weiyang and Huang, Chao},
booktitle={International Conference on Machine Learning},
year={2025},
note={Also available at arXiv:2412.12094}
}